
1. 벡터, 행렬, 배열
이 카테고리의 내용은 파이썬을 활용한 머신러닝 쿡북의 각 챕터별 요약으로 코드는 생략될 수 있습니다.
코드가 필요하신 분들은 아래 GitHub를 통해 확인하세요.
rickiepark/machine-learning-with-python-cookbook
파이썬을 활용한 머신러닝 쿡북. Contribute to rickiepark/machine-learning-with-python-cookbook development by creating an account on GitHub.
github.com
- 넘파이는 파이썬 머신러닝 스택의 기초
- 머신러닝에 자주 사용되는 벡터, 행렬, 텐서같은 데이터 구조에서 효율적인 연산 제공
- 넘파이 연산을 다룸
벡터 만들기
- 넘파이 핵심 데이터 구조는 다차원 배열. 벡터는 1차원 배열로 만듦. 행 또는 열로 가능
- 넘파이 배열은 ndarray 클래스 객체
- ndarray를 사용하여 넘파이 배열 만드는건 비추천
- asarray 함수 사용시 입력이 넘파이 배열일 때 새로운 배열 생성 안함
- array 함수는 입력 배열을 복사할 지 선택하는 copy 매개변수 존재. copy의 기본값은 True -> 배열이 입력되면 복사본 생성.
- 배열을 복사하려면 의도가 명확하도록 배열 객체의 copy 메서드를 사용하는 것이 좋음. copy는 새로운 배열 생성
행렬 만들기
import numpy as np
- np.array 함수를 이용해 넘파이의 2차원 배열(행렬) 만듦.
- 넘파이에 행렬에 특화된 데이터 구조 (np.mat)존재.
- 다음 두 가지 이유로 np.mat 권장하지 않음.
1. 배열이 넘파이 표준 데이터 구조
2. 대부분 넘파이 함수는 행렬 객체가 아니라 배열을 반환한다.
###( ### 주석 ### 이렇게 생각하면 됨)
- np.mat을 권장하지 않는 이유가 이해가 되지 않아 직접 실행해봄.

- np.mat을 이용해 만든 데이터 구조는 행렬 구조이고 np.array를 이용해 만든 데이터 구조는 배열 구조임
- 대부분의 구조가 배열 구조임 그래서 np.mat은 호환이 되지 않아 권장하지 않는다는 뜻
###
- np.empty 함수는 임의의 값이 채워진 배열 생성
- np.zeros 함수는 0으로 채워진 배열 생성
- np.ones 함수는 1로 채워진 배열 생성
- np.full([x, y], z) [x, y] 크기의 행렬의 요소를 전부 z로 채움 # [] 대신 () 사용해도 결과 같음
- 만들어진 배열에 다른 수 사칙연산 가능
희소 행렬 만들기
from scipy import sparse
import numpy as np
matrix = np.array([[0, 0],
[0, 1],
[3, 0]])
matrix_sparse = sparse.csr_matrix(matrix)
- 데이터의 원소는 대부분 0
- 희소 행렬은 0이 아닌 원소만 저장
- 다른 모든 원소는 0이라 가정하므로 계산 비용 크게 감소
print(matrix_sparse)
(1, 1) 1
(2, 0) 3
- 1은 2행 1열, 3은 3행 1열(0부터 시작하므로)에 위치한 0이 아닌 원소임을 나타냄
- 0인 원소를 아무리 추가해도 희소 행렬의 크기는 변하지 않음
- 희소 행렬은 여러 종류 있음. CSC(composed sparse column, 리스트의 리스트, 키의 딕셔너리 등)
- 각각의 차이가 있고 상황에 따라서 적절하게 골라야 함
- 밀집 배열로부터 희소 행렬을 만드는 일은 드묾. 원소의 행과 열의 인덱스를 직접 지정하여 희소 행렬 만들 수 있음
- 희소 행렬을 밀집 행렬로 변환하기 위해 toarray 메서드 사용
- todense 메서드는 np.matrix 객체 반환
원소 선택하기
import numpy as np
vector = np.array([1, 2, 3, 4, 5, 6])
matrix = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])print(vector[:3])
[1 2 3]
print(vector[3:])
[4 5 6]
- :x의 경우 x 포함
- x:의 경우 x 제외
print(matrix[[0, 2]])
[[1 2 3]
[7 8 9]]
print(matrix[[0, 2], [1, 0]])
[2 7]
- 리스트를 전달하여 원소 선택 가능
- 첫번째의 경우 1행과 3행의 원소 출력
- 두번째는 1행 2열, 3행 1열 원소 출력
mask = matrix > 5
print(mask)
[[False False False]
[False False True]
[ True True True]]
print(matrix[mask])
[6 7 8 9]
- boolean mask 배열을 만들어 원소 선택 가능
- 원소 출력 시 True 원소만 출력
행렬 정보 확인하기
import numpy as np
matrix = np.array([[1,2,3,4],
[5, 6, 7, 8],
[9, 10, 11, 12]])matrix.shape
(3, 4)
matrix.size
12- 기본적인 행렬의 모양과 크기
print(matrix.dtype)
int64- 데이터 타입
print(matrix.itemsize)
8- 원소 하나가 차지하는 바이트 크기
print(matrix.nbytes)
96- 배열 전체가 차지하는 바이트 크기
벡터화 연산 적용
import numpy as np
matrix = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])# 100을 더하는 함수
add_100 = lambda i: i + 100
# 벡터화된 함수
vectoried_add_100 = np.vectorize(add_100)
# 행렬의 모든 원소에 함수 적용
print(vectoried_add_100(matrix))
[[101 102 103]
[104 105 106]
[107 108 109]]
# 200을 더하는 함수 (람다 사용 안하고)
def add_200(i):
return i + 200
# 벡터화된 함수
vectoried_add_200 = np.vectorize(add_200)
# 행렬의 모든 원소에 함수 적용
print(vectoried_add_200(matrix))
[[201 202 203]
[204 205 206]
[207 208 209]]- vectorize 클래스는 배열의 일부나 전체에 적용하도록 함수 변환
- vectorize는 기본적으로 원소를 순회하는 for루프 구현한 것 -> 성능 향상 없음
print(matrix + 100)
[[101 102 103]
[104 105 106]
[107 108 109]]- numpy 배열은 차원이 달라도 배열 간의 연산을 수행할 수 있음 ( 브로드 캐스팅 Broadcasting)
matrix = np.array([[1, 1, 1],
[1, 1, 1],
[1, 1, 1]])
print(matrix + [1, 2, 3])
[[2 3 4]
[2 3 4]
[2 3 4]]
print(matrix + [[1], [2], [3]])
[[2 2 2]
[3 3 3]
[4 4 4]]- 브로드 캐스팅은 배열에 차원을 추가하거나 반복해서 배열 크기 맞춤
- (3, 3) 크기 행렬에 (3, ) 크기 벡터를 더하면 (1, 3) 행렬로 변환하여 행을 따라 반복
- (3, 3) 크기 행렬에 (3, 1) 크기 벡터를 터하면 열을 따라 반복
최댓값, 최솟값 찾기
import numpy as np
matrix = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
# 최댓값
np.max(matrix)
9
# 최솟값
np.min(matrix)
1
# 행렬의 각 열의 최댓값
print(np.mat(matrix, axis=0))
[7 8 9]
# 행렬의 각 행의 최솟값
print(np.min(matrix, axis=1))
[1 4 7]- keepdims 매개변수를 True로 지정하면 원본 배열의 차원과 동일한 결과 만듦
vector_column = np.max(matrix, axis=1, keepdims=True)
print(vector_column)
[[3]
[6]
[9]]
print(matrix - vector_column)
[[-2 -1 0]
[-2 -1 0]
[-2 -1 0]]
평균, 분산, 표준편차 계산하기
import numpy as np
matrix = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
# 평균
np.mean(matrix)
5.0
# 분산
np.var(matrix)
6.666666666666667
# 표준 편차
np.std(matrix)
2.581988897471611
# 행렬의 각 열의 평균
print(np.mean(matrix, axis=0))
[4. 5. 6.]- 통계학에서 종종 모집단에서 추출한 샘플의 자유도(degree of freedom)를 고려하여 편향되지 않은 분산과 표준편차 계산
- 훈련 데이터의 독립적인 샘플 수 = 전체 샘플 수 - 1
- np.std, np.var 함수의 ddof 매개변수를 True로 지정하면 편향되지 않은 추정값 얻음
- ddof 매개변수 기본값 = 0
# 편향되지 않은 표준 편차
np.std(matrix, ddof=1)
2.7386127875258306- 판다스(pandas) 데이터프레임(dataframe)의 std 메서드는 ddof 매개변수 기본값 1
import pandas as pd
df = pd.DataFrame(matrix.flatten())
# 편향되지 않은 표준 편차 추정값
df.std()
0 2.738613
dtype: float64
- 실제 머신러닝 모델에서는 자유도 고려 하지 않는 경우가 많음
- 넘파이 mean, std, var 메서드도 keepdims 매개변수 지원
배열 크기 바꾸기
import numpy as np
matrix = np.array([[1,2,3],
[4,5,6],
[7,8,9],
[10, 11, 12]])
# 2x6 크기의 행렬로 바꾸기
# 새로운 행렬은 기존 행렬과 원소 개수 같아야 함
print(matrix.reshape(2, 6))
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]]
# 행렬의 원소 개수
matrix.size
12
# 매개변수 -1은 '가능한 많게'라는 뜻
print(matrix.reshape(1, -1))
[[ 1 2 3 4 5 6 7 8 9 10 11 12]]
# 정수 한 개 입력 시 그 길이의 1차원 행렬 반환
print(matrix.reshpae(12))
[ 1 2 3 4 5 6 7 8 9 10 11 12]
# reshape 매개변수로 -1 입력시 1차원 배열 반환
print(matrix.reshape(-1))
[ 1 2 3 4 5 6 7 8 9 10 11 12]
# ravel 메서드 사용시 1차원 배열 반환
print(matrix.ravel())
[ 1 2 3 4 5 6 7 8 9 10 11 12]
벡터나 행렬 전치하기
import numpy as np
matrix = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
# 전치행렬
print(matrix.T)
[[1 4 7]
[2 5 8]
[3 6 9]]- 선형대수학에서 자주 사용하는 연산
- 각 원소의 행과 열의 인덱스를 바꿈
- 기술적으로 벡터는 단지 값의 모음이기 때문에 전치 불가
# 벡터 전치
print(np.array([1,2,3,4,5,6]).T)
[1 2 3 4 5 6]
# 대괄호 두 번 사용하여 벡터 전치
print(np.array([[1,2,3,4,5,6]]).T)
[[1]
[2]
[3]
[4]
[5]
[6]]
# transpose 메서드를 이용한 전치 행렬
print(matrix.transpose())
[[1 4 7]
[2 5 8]
[3 6 9]]
# 2x3x2 행렬을 2x2x3행렬로 바꿈(2,3번째 원소를 바꿈)
matrix = np.array([[[1,2],
[3, 4],
[5, 6]],
[[7, 8],
[9, 10],
[11, 12]]])
print(matrix.transpose((0, 2, 1)))
[[[ 1 3 5]
[ 2 4 6]]
[[ 7 9 11]
[ 8 10 12]]]
행렬 펼치기
import numpy as np
matrix = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
# flatten 메서드를 이용한 행렬 펼치기
print(matrix.flatten())
[1 2 3 4 5 6 7 8 9]
# reshape 메서드를 이용한 행렬 펼치기
print(matrix.reshape(1, -1))
[[1 2 3 4 5 6 7 8 9]]- reshape 메서드는 넘파이의 뷰를 반환(원래 행렬을 복제). 원본 행렬이 변하면 따라서 변함
- flatten 메서드는 새로운 행렬을 만듦. 원본 행렬이 변해도 변화 없음
# reshape, flatten을 이용하여 각각 행렬 만듦
vector_reshape = matrix.reshape(-1)
vector_flattened = matrix.flatten()
# 원본 행렬 원소 바꿈
matrix[0][0] = -1
# flatten 메서드를 이용하면 새로운 행렬은 만들기 때문에 원소 변화 없음
print(vector_flattened)
[1 2 3 4 5 6 7 8 9]
# reshape 메서드를 이용하면 배열의 뷰를 반환(원본 행렬을 복사)하기 때문에 원본 행렬의 변화를 따라서 변화함
print(vector_reshape)
[-1 2 3 4 5 6 7 8 9]
행렬의 랭크 구하기
# matrix_rank를 이용하여 랭크 반환
import numpy as np
matrix = np.array([[1, 1, 1],
[1, 1, 10],
[1, 1, 15]])
# matrix_rank 메서드를 이용한 matrix 행렬의 랭크
np.linalg.matrix_rank(matrix)
2- 행렬의 랭크는 행이나 열이 만든 벡터 공간의 차원
- 행렬의 랭크(혹은 계수)는 '선형 독립적인' 행 또는 열의 개수
- rank 메서드와 혼동하지 말 것. 넘파이 1.19에서 삭제 예정. rank 메서드 대신 ndim 메서드 사용할 것
- matrix_rank 메서드는 특잇값 분해(singular value decomposition)방식으로 랭크 계산
- linalg 모듈의 svd 메서드로 특잇값을 구한 다음 0이 아닌 값의 수 구함.
# svd 메서드로 특잇값 계산
s = np.linalg.svd(matrix, compute_uv=False)
# 오차를 고려하여 0에 가까운 값을 지정
np.sum(s > 1e-10)
2
# 0도 지정해봄
np.sum(s > 0)
2
행렬식 계산하기
import numpy as np
matrix = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
# 넘파이의 det 메서드 사용하여 행렬식 반환
np.linalg.det(matrix)
0.0- 행렬식은 정방행렬에 의한 선형 변환의 특징을 나타내는 스칼라값
- (2, 2) 크기의 행렬 A = [[a, b], [c, d]] 의 행렬식은 det(A) = ad - bc
행렬의 대각원소 추출하기
import numpy as np
matrix = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
# diagonal 메서드를 이용한 대각 원소 반환
print(matrix.diagonal())
[1 5 9]
# diagonal의 offset 매개변수를 이용하면 주 대각선 주위 대각원소 반환 가능
# 주 대각선 하나 위의 대각원소 반환
print(matrix.diagonal(offset=1))
[2 6]
# 주 대각선 하나 아래의 대각원소 반환
print(matrix.diagonal(offset=-1))
[4 8]- diagonal 메서드는 원본 배열의 뷰를 반환하므로 반환된 배열의 원소를 바꾸려면 배열을 복사하여 사용해야 함
- copy 메서드를 이용하여 행렬을 복사하면 원소 변경 가능
# diagonal 메서드는 원본 배열의 뷰를 반환하므로 원소 변경 불가 -> 오류 발생
a = matrix.diagonal()
a[0] = 10
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-57-88fe5a9b0ebf> in <module>()
----> 1 a[0] = 10
ValueError: assignment destination is read-only
# copy 메서드를 이용하여 만든 배열은 원소 변경 가능
a = matrix.diagonal().copy()
print(a)
[1 5 9]
a[0] = 10
print(matrix)
[[1 2 3]
[4 5 6]
[7 8 9]]- 넘파이의 diag 메서드도 대각원소 반환
- 넘파이의 diag 메서드는 1차원 배열이 주어졌을때 역으로 대각행렬 반환
# 넘파이의 diag 메서드를 이용한 대각원소 추출
a = np.diag(matrix)
print(a)
[1 5 9]
# 넘파이의 diag 메서드는 1차원 배열 입력시 대각 행렬로 반환
print(np.diag(a))
[[1 0 0]
[0 5 0]
[0 0 9]]
행렬의 대각함 계산하기
import numpy as np
matrix = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
# trace 메서드를 사용하여 대각합(대각원소의 합) 반환
matrix.trace()
15
# diagonal, sum 메서드를 이용하여 대각합 구하기
sum(matrix.diagonal())
15
# trace 메서드로 offset 매개변수 사용 가능
# 주 대각선 하나 위의 대각원소 합 구하기
matrix.trace(offset=1)
8
고윳값과 고유벡터 찾기
- 넘파이의 linalg.eig 메서드 사용
import numpy as np
matrix = np.array([[1, -1, 3],
[1, 1, 6],
[3, 8, 9]])
# 넘파이의 linalg.eig 메서드를 이용한 고유값과 고유벡터 값 구하기
eigenvalues, eigenvectors = np.linalg.eig(matrix)
# 고유값
eigenvalues
array([13.55075847, 0.74003145, -3.29078992])
# 고유벡터
eigenvectors
array([[-0.17622017, -0.96677403, -0.53373322],
[-0.435951 , 0.2053623 , -0.64324848],
[-0.88254925, 0.15223105, 0.54896288]])- 고유벡터는 머신러닝 라이브러리에서 널리 사용
- 행렬 A로 표현되는 선형변환 적용 시 고유벡터는 스케일만 바뀌는 벡터(방향은 x)
- 공식으로 나타내면 Av = λv
- A가 정방행렬일 때 λ는 고윳값, v는 고유벡터
- 대칭행렬일 경우 linalg.eigh 메서드를 이용하여 고윳값, 고유벡터 더 빠르게 계산 가능
- (주의) linalg.eigh 메서드는 입력값이 대칭행렬인지 검사 안함
# 대칭행렬
matrix = np.array([[1, -1, 3],
[-1, 1, 6],
[3, 6, 9]])
# 대칭행렬의 경우 linalg.eigh 메서드 이용
eigenvalues, eigenvectors = np.linalg.eigh(matrix)
# 고윳값
eigenvalues
array([-3.47535395, 1.84536862, 12.62998534])
# 고유벡터
eigenvectors
array([[-0.48107069, -0.85602522, 0.18918723],
[-0.73926367, 0.51210152, 0.43731139],
[ 0.47123265, -0.07051844, 0.87918538]])
점곱 계산하기
import numpy as np
# 벡터 생성
vector_a = np.array([1,2,3])
vector_b = np.array([4,5,6])
# 넘파이의 dot 메서드를 이용한 점곱
np.dot(vector_a, vector_b)
32- 두 벡터의 점곱은 아래 그림과 같이 정의
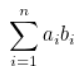
- ai는 벡터 a의 i 번째 원소
- 넘파이 dot 메서드를 사용하여 점곱 가능
- 파이썬 3.5 이상에서 @ 연산자 사용 가능
# @ 연산자를 이용한 점곱
vector_a @ vector_b
32
- (주의) @ 연산자는 np.dot이 아니라 np.matmul 메서드. 스칼라 베열에 사용 불가
# 스칼라 배열 생성
scalar_a = np.array(1)
scalar_b = np.array(2)
# 넘파이의 dot 메서드 이용한 점곱(결과 잘 나옴)
np.dot(scalar_a, scalar_b)
# @ 연산자 이용시 오류
scalar_a @ scalar_b
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-85-019764208522> in <module>()
----> 1 scalar_a @ scalar_b
ValueError: matmul: Input operand 0 does not have enough dimensions (has 0, gufunc core with signature (n?,k),(k,m?)->(n?,m?) requires 1)
행렬 덧셈과 뺄셈
import numpy as np
# 행렬 생성
matrix_a = np.array([[1, 1, 1],
[1, 1, 1],
[1, 1, 2]])
matrix_b = np.array([[1, 3, 1],
[1, 3, 1],
[1, 3, 8]])
# 행렬 덧셈
np.add(matrix_a, matrix_b)
array([[ 2, 4, 2],
[ 2, 4, 2],
[ 2, 4, 10]])
# 행렬 뺄셈
np.subtract(matrix_a, matrix_b)
array([[ 0, -2, 0],
[ 0, -2, 0],
[ 0, -2, -6]])
# 간단히 +, - 이용하여 덧셈, 뺄셈 가능
matrix_a + matrix_b
array([[ 2, 4, 2],
[ 2, 4, 2],
[ 2, 4, 10]])
행렬 곱셈
- 넘파이의 dot 메서드 사용
import numpy as np
# 행렬 생성
matrix_a = np.array([[1, 1],
[1, 2]])
matrix_b = np.array([[1, 3],
[1, 2]])
# 넘파이의 dot 메서드 사용하여 행렬 곱셈
np.dot(matrix_a, matrix_b)
array([[2, 5],
[3, 7]])
# @ 연산자 이용하여 행렬 곱셈
matrix_a @ matrix_b
array([[2, 5],
[3, 7]])
# * 연산자로 원소별 곱셈
matrix_a * matrix_b
array([[1, 3],
[1, 4]])
- np.dot 메서드는 다차원 배열에도 적용 가능
- 첫번째 배열의 마지막 차원과 두번째 배열의 끝에서 두번째 차원이 같아야 함
- (a, b, c, D) 크기의 배열과 (e, f, D, h) 크기의 배열
- 두 배열의 점곱 결과는 (a, b, c, e, f, h) 크기의 배열
- (주의) np.matmul과 @ 연산자는 다차원 배열을 마지막 두 차원이 단순히 쌓인것으로 취급
- np.matmul과 @ 연산자를 적용하기 위해서는 각 차원의 크기가 같거나 한 차원이 1이어야 함(a, e가 같거나 한쪽이 1 ...)
- 연산 결과는 (a', b', c, h), a'는 a와 e 중에서 1이 아닌값, b'는 b와 f중에서 1이 아닌 값
# 행렬 생성
a = np.random.rand(2, 1, 4, 5)
b = np.random.rand(1, 3 ,5, 6)
# np.dot 메서드 사용한 배열의 크기
np.dot(a, b).shape
(2, 1, 4, 1, 3, 6)
# np.matmul 메서드 사용한 배열의 크기
np.matmul(a, b).shape
(2, 3, 4, 6)
역행렬
- 넘파이의 linalg.inv 메서드 이용
import numpy as np
matrix = np.array([[1, 4],
[2, 5]])
# np.linalg.inv 메서드를 이용하여 역행렬 구하기
np.linalg.inv(matrix)
array([[-1.66666667, 1.33333333],
[ 0.66666667, -0.33333333]]) - 정방행렬 A의 역행렬은 다음 식의 두번째 행렬 A^-1

- I는 단위행렬
- A의 역행렬이 존재한다면 linalg.inv 메서드로 구할 수 있음
- 행렬과 그 행렬의 역행렬을 곱하면 단위행렬 나옴
# 행렬과 역행렬 곱
matrix @ np.linalg.inv(matrix)
array([[1.00000000e+00, 0.00000000e+00],
[1.11022302e-16, 1.00000000e+00]])
# 정방행렬이 아닌 행렬의 역행렬(유사 역행렬)은 np.pinv 메서드 이용
matrix = np.array([[1,4,7],
[2,5,8]])
np.linalg.pinv(matrix)
array([[-1.16666667, 1. ],
[-0.33333333, 0.33333333],
[ 0.5 , -0.33333333]])
난수 생성하기
import numpy as np
# 결과를 동일하게 하기 위해 초기값 설정
np.random.seed(0)
# 0.0과 1.0 사이에서 세 개 실수 난수 생성
np.random.random(3)
array([0.5488135 , 0.71518937, 0.60276338])
# 1과 10 사이에서 세 개 정수 난수 생성
np.random.randint(0, 11, 3)
array([3, 7, 9])
# 설정한 분포에서 난수 생성 가능
# 평균 0.0, 표준편차 1.0인 정규분포에서 세 개 난수 생성
np.random.normal(0.0, 1.0 ,3)
array([-1.42232584, 1.52006949, -0.29139398])
# 평균 0.0, 스케일 1.0인 로지스틱 분포에서 세 개 난수 생성
np.random.logistic(0.0, 1.0, 3)
array([-0.98118713, -0.08939902, 1.46416405])
# 1.0보다 크거나 같고 2.0보다 작은 세 개 난수 생성
np.random.uniform(1.0, 2.0, 3)
array([1.47997717, 1.3927848 , 1.83607876])- random, sample 메서드는 random_sample 메서드의 단순 별칭
- uniform 메서드에 최솟값을 0.0, 최댓값을 1.0으로 지정한 것과 동일
- np.random.random((2, 3)) = np.random.sample((2, 3)) = np.random.uniform(0.0, 1.0, (2, 3))
np.random.random_sample((2, 3))
array([[0.33739616, 0.64817187, 0.36824154],
[0.95715516, 0.14035078, 0.87008726]])
# rand 함수는 크기를 튜플이 아니라 개별적인 매개변수로 전달
np.random.rand(2, 3)
array([[0.47360805, 0.80091075, 0.52047748],
[0.67887953, 0.72063265, 0.58201979]])
# randint 함수는 최솟값을 포함하고 최댓값은 포함하지 않는 정수 난수 생성
# random_integers 함수는 최댓값도 포함하나 삭제될 예정이므로 randint 사용 권함
np.random.randint(0, 1, 10)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
# standard_normal 함수로 평균 0.0, 표준편차 1.0인 정규분포의 난수 생성
np.random.standard_normal((2, 3))
array([[-0.13309028, 1.59456053, 0.23043417],
[-0.06491034, -0.96898025, 0.59124281]])
# randn 함수는 크기를 튜플이 아니라 개별적인 매개변수로 전달
np.random.randn(2, 3)
array([[-0.7827755 , -0.44423283, -0.34518616],
[-0.88180055, -0.44265324, -0.5409163 ]])
# 그 외 자주 사용하는 함수들
# choice 함수는 배열의 원소 중에서 랜덤하게 지정된 횟수만큼 샘플 만듦
# 또는 0~정수-1 사이에 원소 중에서 램덤하게 원소 선택
np.random.choice([0, 1, 2], 5)
array([0, 1, 2, 2, 0])
# shuffle 함수는 배열 섞음
a = np.array([0, 1, 2, 3, 4])
np.random.shuffle(a)
a
array([0, 2, 3, 4, 1])
# permutation 함수는 입력된 배열의 복사본을 만들어서 섞은 후 반환
# 정수를 입력하면 0에서부터 정수-1까지 숫자 섞은 후 반환
np.random.permutation(a)
array([2, 0, 1, 3, 4])
np.random.permutation(5)
array([4, 1, 2, 0, 3])'컴퓨터 > 파이썬을 활용한 머신러닝 쿡북' 카테고리의 다른 글
| 2. 데이터 적재 (0) | 2020.07.17 |
|---|---|
| 21. 훈련된 모델 저장과 복원 (2) | 2020.06.19 |
| 18. 나이브 베이즈 (0) | 2020.06.19 |



댓글